
ESMFold2 is a sequel to the popular ESMFold model, an entirely self-supervised alternative to AlphaFold 2 for protein 3D structure prediction. The core thesis of ESMFold2 is that, unlike methods such as AlphaFold 3 that rely on extensive evolutionary sequence databases to achieve high prediction accuracy, strong structure prediction accuracy can be obtained by conditioning a diffusion model on the representations of a large, pretrained (protein) language model (ESMC-6B).
The authors show that, by scaling up the language model used for sequence embedding → diffusion conditioning, they observe robust neural scaling. The method seems to work well for a range of structure prediction tasks, including those assessing protein-protein and protein-ligand interactions, which are critical for many drug discovery efforts today. Overall, this work points to a possible future in AI4Science where integrating less domain knowledge (e.g., in the form of hand-crafted biological sequence knowledge) may open the door to true (NLP-like) neural scaling for scientific applications, unlocking new methodological capabilities along the way.
What’s more, ESMFold2’s source code is available on GitHub!
Recently, multiple research groups (from MIT and ICL) have found that scientific foundation models, representing both organic and inorganic matter, converge to similar representations of their input data (with or without representational alignment). This suggests that these models are implicitly learning shared principles of the underlying data they are trained on, regardless of neural architecture or training methodology. A caveat noted by the latter research group, however, is that self-supervised generative models (of materials) tend to produce divergent representations when not trained to predict physical properties (e.g., energies, forces) using ground-truth labels available for supervision.
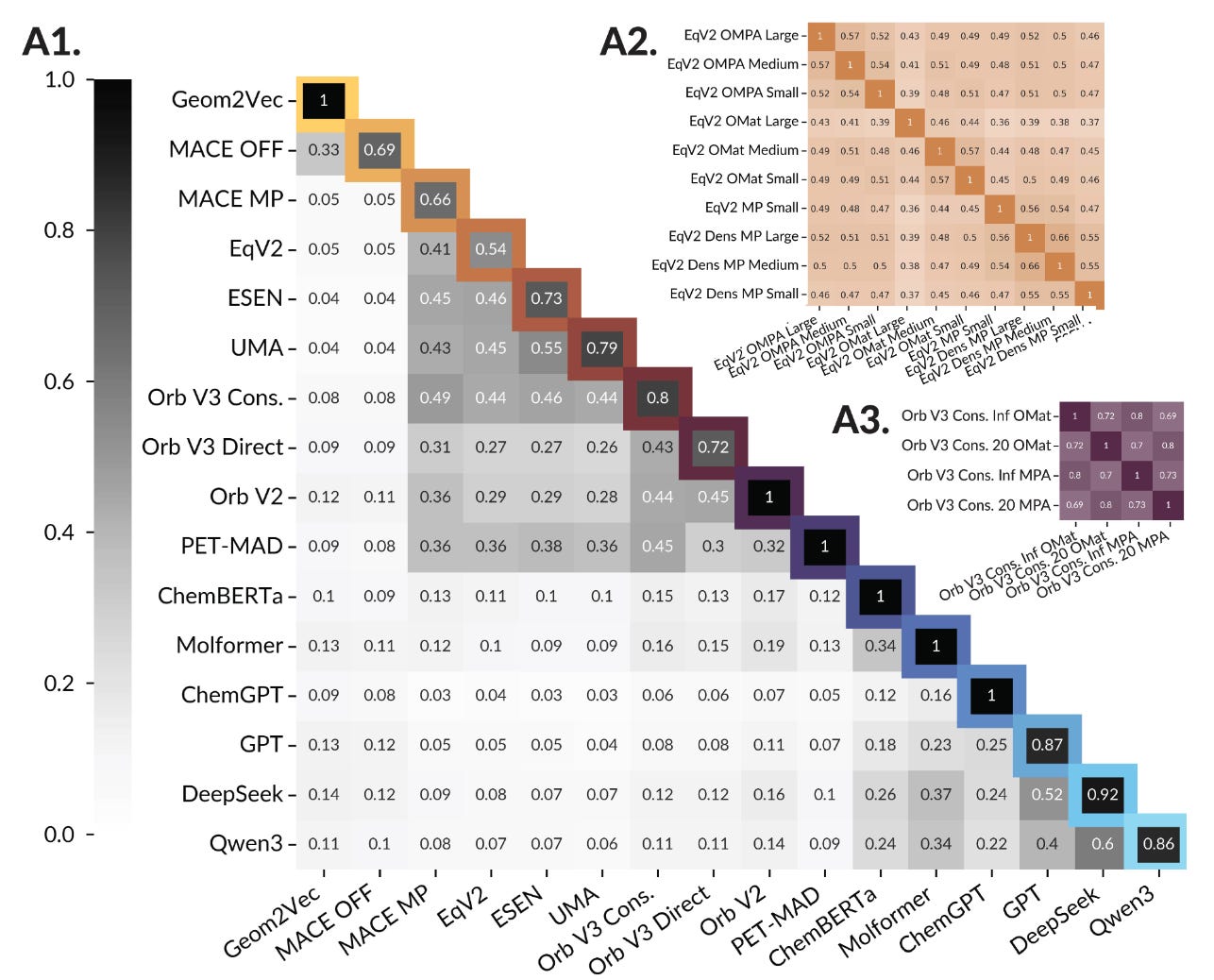
An open question is whether this divergence trend holds for all types of generative models or only those that align diverse modalities (e.g., text, graphs) as a conditioning prior. Additionally, it is unclear if autoregressive generative models would face such limitations. Fortunately for future studies, the source code accompanying ICL's findings is available on GitHub.
What are your thoughts on the future of self-supervision in AI4Science? Do you see a need for supervising physical predictions (e.g., of molecular properties) during model pretraining, or can/should models be able to learn rich, physically-meaningful representations from self-supervision alone?