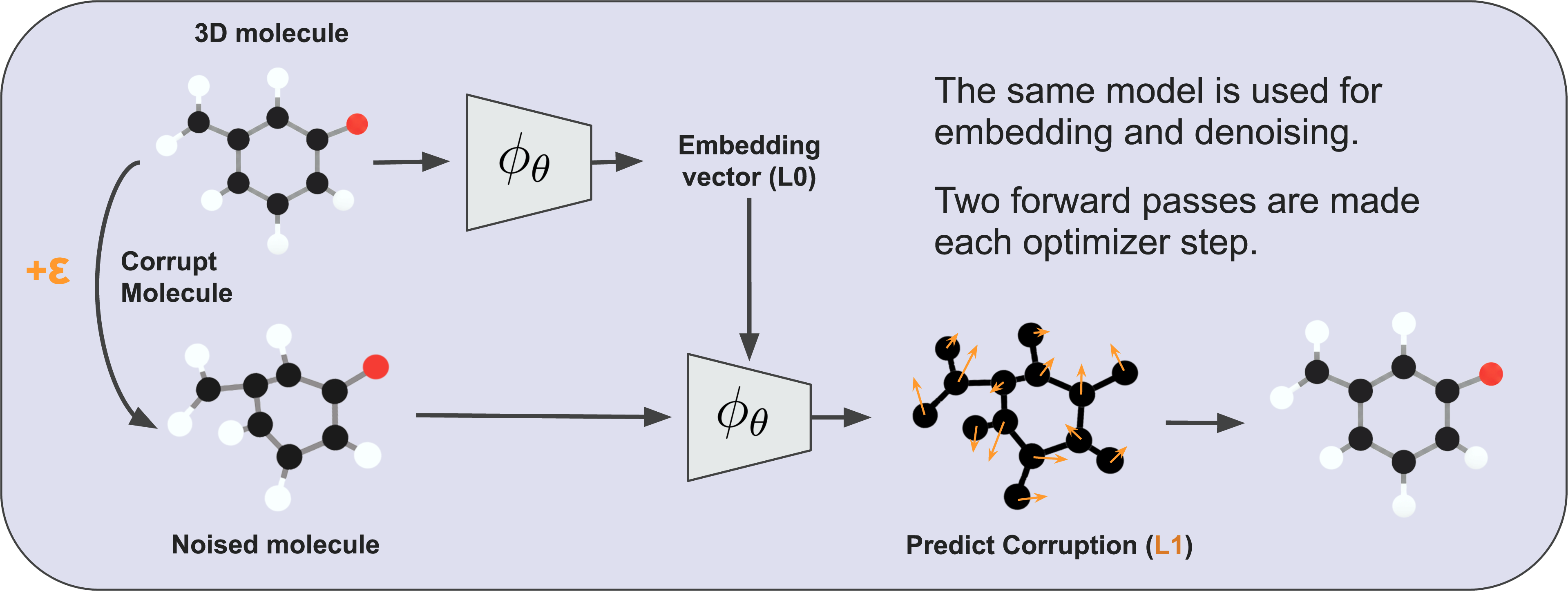
Self-supervised learning is the default method of choice for pretraining image, text, and audio foundation models, and the same conventions hold for scientific data. The question in scientific machine learning is, do default approaches to self-supervised learning work best, or might they benefit from a bit of extra insight to learn what we want them to? Self-Conditioned Denoising, a new pretraining method for atomic data, makes a strong case for the latter.
As it turns out, deep learning models of 3D atomistic systems benefit considerably from a latent prediction pretraining objective commonly used with joint-embedding predictive architectures (JEPAs), where the model is structurally encouraged to learn embeddings of clean atomic data that, when condensed into global molecular representations, serve as useful context for denoising noisy atomic data. This pretraining setup pushes deep learning models to pick up on local and global semantics of geometric atomic data, where local corruptions of atomic coordinates may change the global features of a molecule (and vice versa). If you are curious to learn more about this approach, its source code is openly available.
Yann Lecun and other AI researchers have long been voicing the need for self-supervised/world modeling techniques that intrinsically learn physically-meaningful embeddings of real-world (e.g., video) data. With LeWorldModel, such thinkers are taking a step towards realizing more robust training methods for physical world models. One kind of question this work naturally raises is, would this work well for scientific (e.g., heterogeneous) data? And how sensitive would this approach be to noisy artifacts present in real-world physical/chemical/biological datasets?
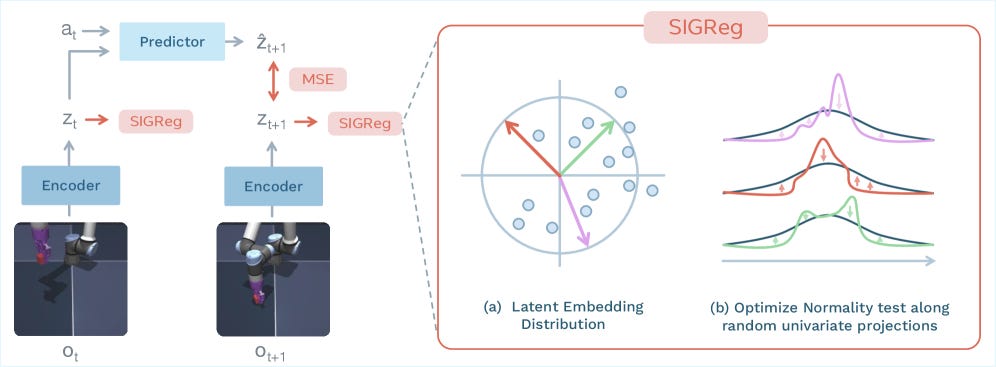
For now, this method has been evaluated using well-known (robotics-focused) planning benchmarks. It remains to be seen whether or how this training technique will surface in scientific disciplines. Fortunately, for those curious to learn more and perhaps explore such possibilities, its source code is freely available.
Will world models one day bridge traditional boundaries between scientific disciplines? Or is more value to be found in specializing such models for specific domains of data? What are your thoughts?