Protein folding (and biomolecular co-folding more generally) is a fundamental task in structural biology, underpinning some of the most complex biological functions necessary for the development and maintenance of living systems. In the last few years, we have seen significant methodological strides in developing AI models for this scientific domain, introducing (now ubiquitous) computational algorithms such as AlphaFold by Google DeepMind. AlphaFold 3, in particular, pushed the field forward with its hallmark ability to model arbitrary combinations of 3D biomolecular interactions.
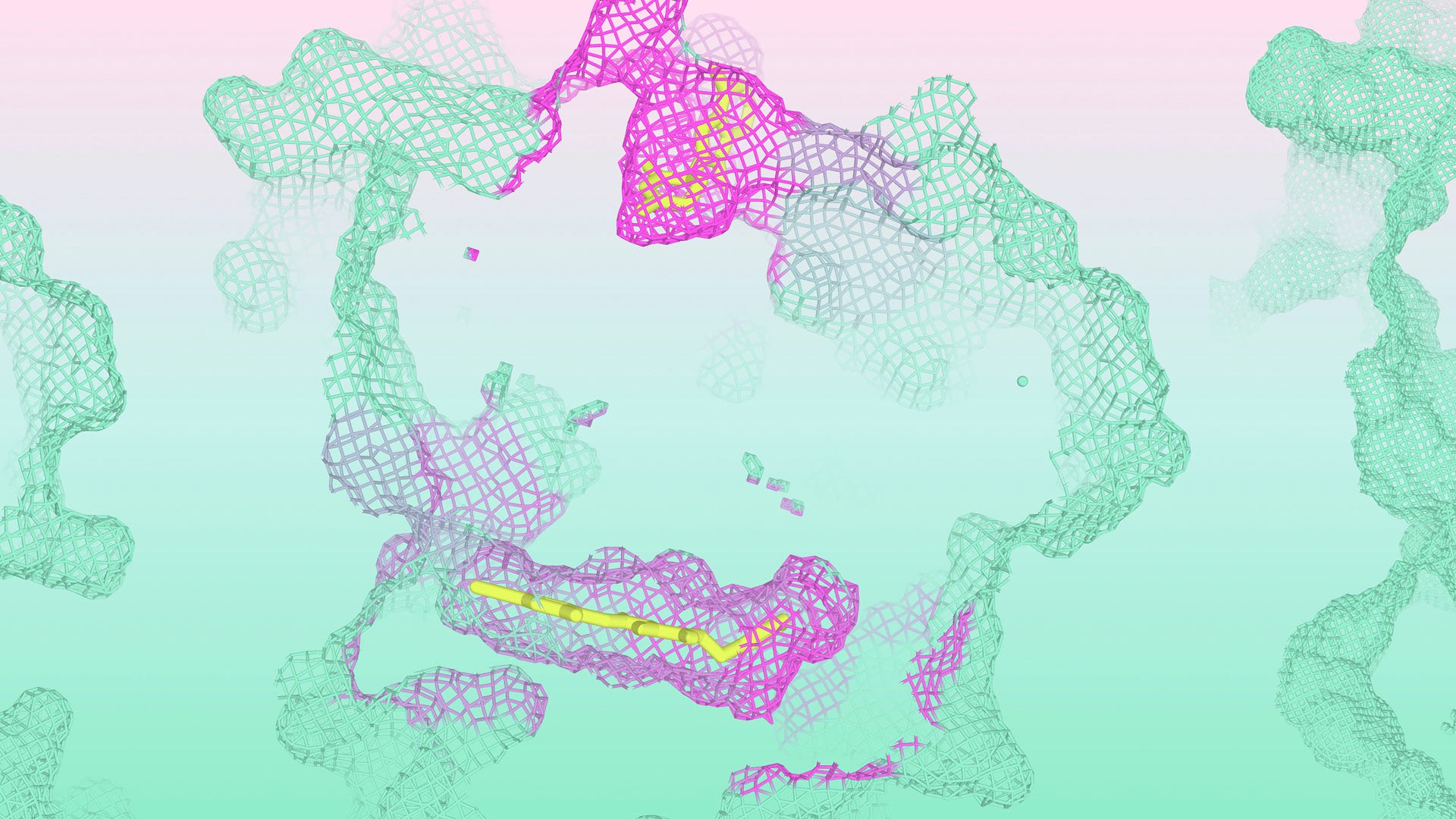
Now, DeepMind (technically Isomorphic Labs) has announced an enhanced version of AlphaFold 3 (AF3) that they call the Isomorphic Labs Drug Design Engine (IsoDDE), which purportedly surpasses the accuracy of AF3 in predicting increasingly novel types of biomolecular interactions not found in the algorithm’s training dataset. While impressive, without the availability of an API for model inference, it is currently impossible for third-party researchers to verify these claims. As such, the announcement of IsoDDE signals a step change in the AI4Science research community, namely that going forward, industry research labs may become increasingly emboldened to delay or deny open-source/API software releases for newly announced AI models, partially disrupting (in my view) a healthy research ecosystem built upon third-party validation of reported results. To give the team at Isomorphic Labs (Iso) appropriate credit, it goes without saying that the computational results they (purportedly) achieved with IsoDDE are compelling and warrant further study, which is why third-party validation of their new models should (in time) only strengthen their messaging.
One final point to consider is that Iso has (currently) only reported results for predicting protein-ligand (and protein-protein) binding structures and affinities. Why might that be? Is IsoDDE specialized for these types of interactions, suggesting they found including RNA/DNA data in its training procedure was a hindrance to achieving the most compelling performance? Or is Iso still hyperparameter-tuning the model to balance its performance across all types of biomolecular interactions? If the former is true, this brings into question one of the central theses of AF3, that the current generation of generative AI models (namely diffusion models) mutually benefit from modeling all types of biomolecular interactions simultaneously (via a mechanism like transfer learning). If the latter is true, perhaps IsoDDE is no longer a standard diffusion model (in the spirit of AF3)? For now, the best we can do is speculate. And more importantly, the ultimate litmus test of IsoDDE will be wet-lab validation, which Iso has not yet discussed for this new model.
Over the last year or so, there’s been a strong push to unify different data domains of chemistry with unified (multimodal) AI architectures, mostly on the generative modeling side of things. However, one step that’s important to take is to measure how well generative AI models can learn representations applicable to a variety of related prediction tasks, along the path to developing what fields such as computer vision and natural language processing would call a Chemical “Foundation Model” (and to do so in an open-source and reproducible manner). In this spirit, the recently released Zatom-1 model is the first fully open-source foundation model for 3D molecular and material science, bridging generative and predictive tasks for 3D chemistry (disclosure: conflict of interest).
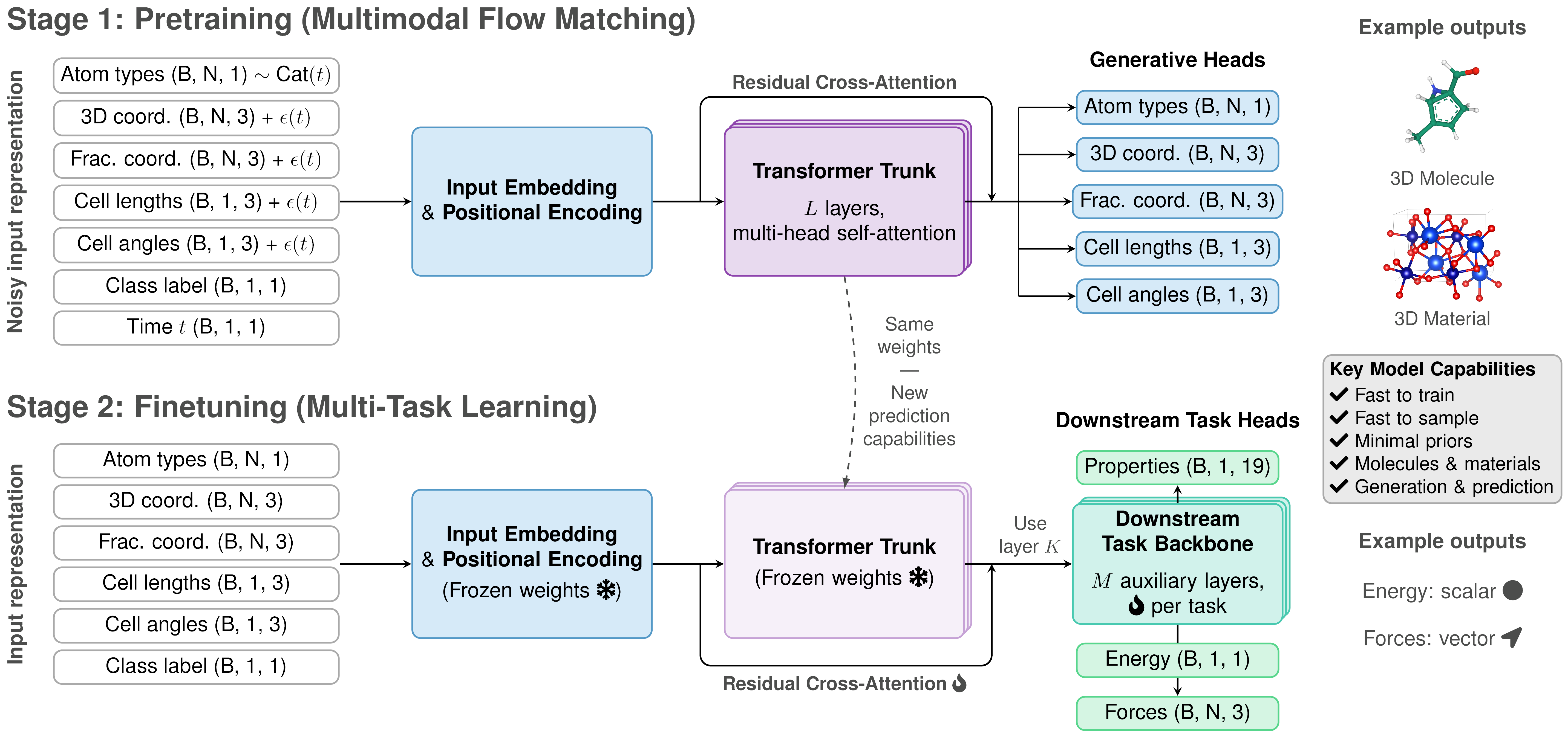
What remains to be seen is whether this all-atom approach to foundation modeling of 3D chemical systems can generalize to larger (biological) systems, such as protein or RNA biomolecules, and can handle significant distribution shifts compared to its training data. Given the number of successful examples of all-atom generative models, such as AF3, this path to AI-based atomistic modeling may be appealing from a theoretical and practical lens.
What are your thoughts? Do you think bidirectional networks, like diffusion models (e.g., AF3), will stand the test of time, or will domain-specific autoregressive models (like scientific large language models) surpass them in terms of scale and flexibility at inference time? Varied opinions are welcome.